

Data Leadership
Engineering a New Data Tool – and 5 Ways to Do It Better
Published
October 30, 2024
Read Time
6 minutes
Topics
Data leadership in action
, Building an organization

Read Time
6 minutes
Topics
Data leadership in action
, Building an organization
How does a civil engineer with a degree from the University of Virginia end up creating an interactive visualization for siting commercial businesses that a Geographic Information Systems (GIS) Specialist calls “the coolest thing I’ve ever seen?”
Like any worthwhile effort, it wasn’t an overnight success story. Similar to a lot of aspiring data leaders, I stumbled into the field due to a convergence of curiosity, a specific set of needs and a deeply rooted love for problem-solving.
Growing up, computers always fascinated me and I remember constantly experimenting with the most efficient ways to do various digital tasks. Later in life, I turned to the same curious exploration as I tackled new problems in college, internships, and the workplace. Over time, that evolved into using much larger data sets and tools specifically designed for managing them. I also drew inspiration from my mom, who was a proto-systems engineer and ended up running all the computer systems for the company her dad started.
As a civil engineer, my education and early career revolved around understanding and designing sites, utilities, and infrastructure to take a client’s vision and make it a reality. Our company, Timmons Group, also focuses heavily on multiple other fields of practice to give our clients more of a wraparound service experience. One of those services is GIS – using hundreds of GIS professionals to help our clients with various services.
We believe, and practical experience has borne out, that the earlier we can get involved with potential clients, the better – and that’s where this story really starts. As an Economic Development team, we brainstormed that if we could help people find and select a site, help evaluate that site on all relevant criteria in the early stages, then we would have the deepest experience on the site when it came time for the client to interview for who would provide the engineering services.
A crash course in data
This vision, originally cast by my boss, was a top priority as soon as I joined the company in 2013. While still responsible for engineering-related work, my boss gave me six weeks from my first day to learn GIS. A year later, we initiated a pilot project in collaboration with our GIS group to pursue this idea of using engineering expertise within GIS data to enhance site selection. The Roanoke Valley of Virginia – my hometown area – was the innovative region that initiated this project. During our planning and dreaming, we decided to term this process ADDSS – Analytical Data-Driven Site Selection.
At its core, we wanted the ADDSS process to capture both our engineering expertise – detailed knowledge on land development, utilities, roads and other infrastructure elements – and the data-driven nature of our GIS expertise. This meant using GIS to find good “dirt” (industry nickname for land) that hadn’t already been found or developed. We needed to harness the power of GIS data and enrich it with our engineering expertise to use this composite to assess viability based on the market demand for sites. We also needed to develop the ability to look in a way that no one else could – not just at a single parcel but at all the surrounding land – to consider any potential option. This led us to develop dozens of methods to assess proximity to roads and utilities, the potential of neighboring land, and overall developability of every parcel. It was a daunting task.
Beyond the black box
Although our early attempts in GIS were successful, including that initial pilot project, each new project uncovered fresh questions and challenges that required evolving our process to provide better service to our clients. The first, and largest, issue we ran into over our decade of iterations we came to designate as “the black box issue.”
Our initial “tools” (a term we would come to use when discussing the final product used in site selection) consisted of massive models processing hundreds of layers based on industry-standard knowledge about slope thresholds, wetland coverages and even client-based criteria for avoidance or proximity. These models would feed in parameters, get a dataset as output, but leave no trace of why certain parcels were eliminated. Of course, that begged the question, “What about that parcel next to it?”
After being asked this question dozens of times, my half-joking response was, “What if we just did everything? Analyzed every parcel through every possible parameter or iteration?” Half-joking because, while the idea made some sense to me, it also entailed running hundreds of data layers across an average of 60,000 parcels for each locality. I knew it was possible but, at the time, I had no concrete path laid out to achieve this. When my boss’s response was, “Let’s do it,” I needed to go back to the drawing board to figure out how to organize and integrate the billions of resulting data points. Each layer can have anywhere from a single important data point to a dozen, while slope layers could start in the billions once prepped for analysis.
By 2019 our efforts had paid off in many ways. We had multiple aspects of our work beginning to converge after winning a statewide project to evaluate 460 existing sites. This effort, requiring coordination of over 1,000 stakeholders in updating a large existing database of site information, not only brought together our growing GIS capabilities but also exposed us to Tableau. All it took was one demonstration for my boss to task me with figuring out a way for us to use it. A few weeks later, I knew it contained the missing puzzle piece we had been looking for to solve our biggest hurdle – “the black box issue.”
That was a breakthrough period for us. Aside from the 4,000+ hours of my time we had invested in developing the process and learning from mistakes, we decided to invest in a new computer system to remove the hardware limitations during the processing side of our method. This new hardware, combined with several other software advancements and adjustments to our process, provided the key elements we needed to build upon the years of foundational work we’d completed. Now, I could process in minutes what used to take hours on every single parcel – hundreds of layers of information about slope, elevation ranges and proximity of wetlands, every facet of a site you could imagine – and tie it all together with Tableau.
The resulting analysis capabilities surprised even us. Our typical project, as I had guessed before, now measured the overall data points processed by the billions rather than the thousands. After some trial and error, we even completed statewide projects that looked at every potential industrial parcel in two states. And we were able to answer the “What about that parcel next to it?” question, since we had already run everything.
What our process has evolved into revolves around a core principle of efficiency that’s hardwired into my bones – let each software do what it’s best at in each step of the process. GIS is an incredibly robust tool for spatial analysis but it is not ideal for organizing and cleaning hundreds of large databases. Tableau Prep or other similar software is fantastic at prepping data in a repeatable way over multiple projects and ensuring a clean, uniform dataset. Tableau excels at multi-parameter, large dataset analysis with visualization. So in each step of our process we are ceaselessly asking the question, “Is there a more efficient way to do this?”
In its current state, our “tools” create interactive visualizations where we can run dozens of queries on hundreds of thousands of land parcels within seconds. We seek to answer all the key questions surrounding site selection and development, from developable acreage and elevation change to neighboring owners and airport proximity, all within a custom-built solution for each client.
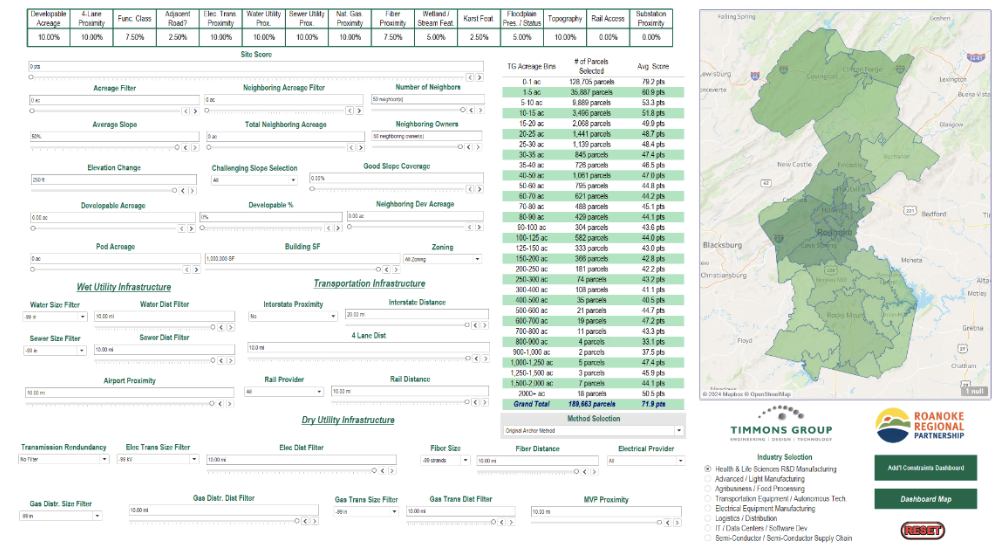
A few parameters for success
If you and your team find yourselves facing an analysis challenge that is made problematic by a mountain of data, here are a few guidelines I have found helpful from my experiences with civil engineering and data analysis.
- Respect your audience’s expertise and your own. Our clients, especially clients like global car manufacturers, tend to know exactly what they want. We must respect that, but what they don’t know is how that connects with the aspects of a site they aren’t experts in. That’s where we put both our engineering expertise and our GIS data to use. What looks good to some might not have the right infrastructure or might be very difficult to acquire from multiple landowners, or could have design challenges that preclude the site ever being developed.
- Research the data that’s critical to know. For some land developers, the nearby presence of endangered species areas, wildlife management areas, conservation lands, or conservation easements is a red flag. For others, it’s critical to know where robust infrastructure intersects with the right tax structure to provide them a competitive edge. This also applies to regions and land areas, as some areas will require a unique approach to approximating wetland locations while others will require a deeper study into topography or karst features. Make sure your data model is adding in all the right parameters to analyze and not leaving anything out.
- Let technology do what it does best. Harnessing the power of technology appropriately is key to our process. We never want to use a screwdriver to hammer a nail – we’d rather use a hammer or, even better, a nail gun. Find the right fit and sweet spot with what a piece of technology does best and try to limit pushing it into areas where it’s not as strong as another software. Similarly, this applies to the divide between what technology is best suited to do versus what the human brain is best suited to do. Our best sites don’t come straight from the computer but often the computer sifts through the billions of options to show us where we need to look – then we finish it off with our expertise. As we turn the dials up and down on parameters, we get a better feel for the relative strengths and weaknesses of the model and its results. This is also an argument for allowing the brain (in this case, the engineer’s brain) to do what it still does better than any AI.
- Focus on an intuitive user interface. No matter how many parameters in your data set, make sure everyone in the potential audience can pull the information they need to make the right decisions. This principle carries over directly from our engineering world – no matter how amazing your design or data model is, if no one can understand and build it (use it effectively, in this case) then it is useless. Keep an eye towards this even as you build and structure the data itself to ensure it’s intuitive for another person to use.
- Release, refine, release. No one’s first version of anything is perfect, so be open to building in improvements to your data model as its shortcomings or limitations become clear. Throughout the lifecycle of our process, our latest iteration is the result of at least 50 prior versions – each of which had points that I took issue with and wanted to improve. However, many of those issues weren’t visible to me until I’d fixed the three before it. As you build, always keep an eye towards the next item you can improve without allowing it to slow down your current project.

